
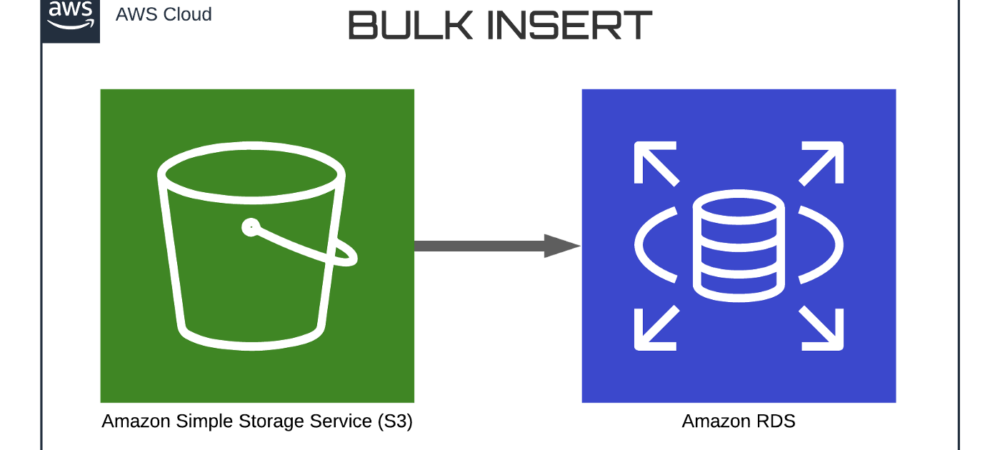
Nous souhaitons importer des données d’Amazon S3 vers une base de données RDS SQL Server.
Amazon Web Service (AWS) possède une fonctionnalité qui permet une intégration native entre Amazon RDS SQL Server et Amazon S3. Grâce à cette intégration, il est désormais possible d’importer des fichiers d’un compartiment Amazon S3 dans un dossier local de l’instance RDS. De même, les fichiers de ce dossier peuvent être exportés vers S3. Le chemin du dossier local RDS est D:\S3\. Cette intégration est un excellent moyen d’importer des données dans des bases de données RDS SQL Server sans utiliser d’outil ETL. Les fichiers de données S3 téléchargés sur le disque local peuvent être facilement ingérés à l’aide de la commande BULK INSERT.
Scénario de test
Dans cet article, nous verrons comment préparer un RDS SQL Server pour une intégration S3 native. Nous allons copier quelques fichiers de données d’un compartiment S3 vers l’instance RDS, puis ingérer ces données dans une base de données.
Source de données
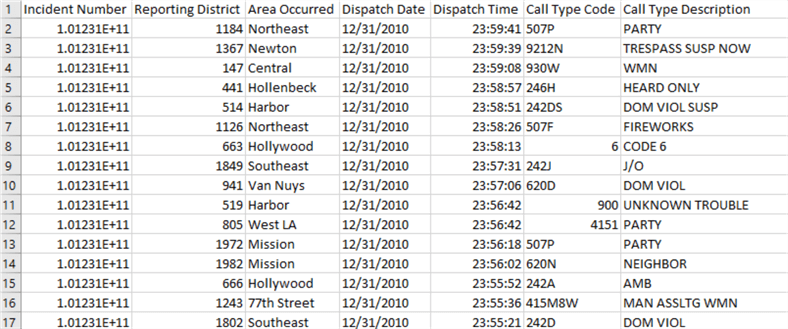
Pour notre exemple, nous allons prendre un fichier Excel avec des données anonymisés. Le fichier est au format CSV et possède des lignes d’en-tête.
Vous pouvez télécharger une copie de ce fichier pour s’exercer
L’image ci-dessous montre un échantillon des données :
Emplacement de la source S3
Nous avons copié les fichiers dans un dossier nommé « data » dans un bucket S3 :
Et nous avons donc mis nos fichiers :
Instance de serveur SQL RDS
Nous avons créé une seule instance AZ RDS SQL Server 2017 dans la même région que le compartiment S3 (us-east-1, Virginie du Nord) :
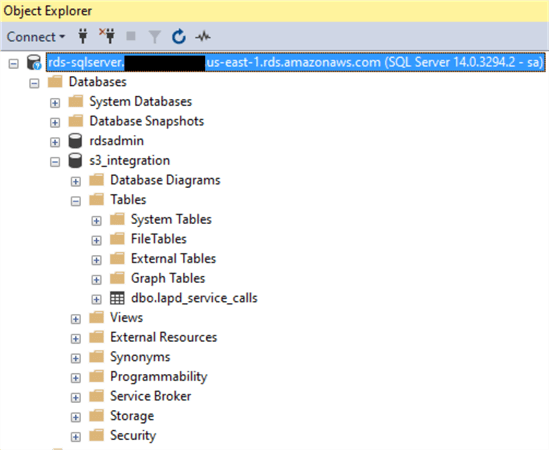
Base de données et table de destination
Nous avons créé une base de données appelée « s3_integration« , et y avons également créé une table appelée « lapd_service_calls« . Les champs de la table représentent les colonnes du fichier source.
-- Create destination database
CREATE DATABASE [s3_integration]
CONTAINMENT = NONE
ON PRIMARY ( NAME = N's3_integration', FILENAME = N'D:\rdsdbdata\DATA\s3_integration.mdf' , SIZE = 102400KB , FILEGROWTH = 131072KB )
LOG ON ( NAME = N's3_integration_log', FILENAME = N'D:\rdsdbdata\DATA\s3_integration_log.ldf' , SIZE = 25600KB , FILEGROWTH = 32768KB )
GO
USE s3_integration
GO
-- Create destination table
CREATE TABLE lapd_service_calls
(
incident_number varchar(20) NOT NULL,
reporting_district varchar(20) NOT NULL,
area_occurred varchar(20) NOT NULL,
dispatch_date varchar(30) NOT NULL,
dispatch_time varchar(20) NOT NULL,
call_type_code varchar(20) NOT NULL,
call_type_description varchar(30) NULL
)
GO
Bien que certains des champs des données source soient de type numérique (numéro d’incident) ou de date (date d’expédition), nous spécifions chaque champ en tant que varchar pour simplifier le processus de chargement.
Configuration de l’intégration S3
Nous allons maintenant configurer l’instance RDS pour l’intégration S3.
Étape 1 : Création d’une stratégie et d’un rôle IAM
La première étape de l’intégration de RDS SQL Server à S3 consiste à créer un rôle IAM avec accès au compartiment et aux dossiers S3 source.
Connectez vous sur AWS et Rendez vous dans l’interface de création des IAM.
Menu Access Management > Policies
Ensuite bouton « create policies ».
choisir S3 comme Service
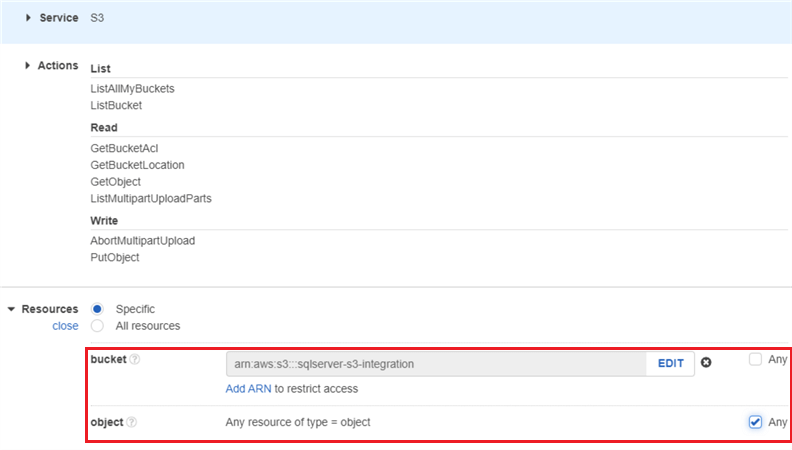
Ensuite, nous attribuons des autorisations S3 à la stratégie :

Nous spécifions la ressource S3 sur laquelle ces autorisations s’appliqueront. Dans ce cas, nous fournissons l’ARN (Amazon Resource Name) du compartiment S3 source. Nous sélectionnons l’option pour inclure tous les objets (y compris les dossiers) sous ce bucket :
Enfin, nous ajoutons un nom et un descriptif à notre stratégie IAM
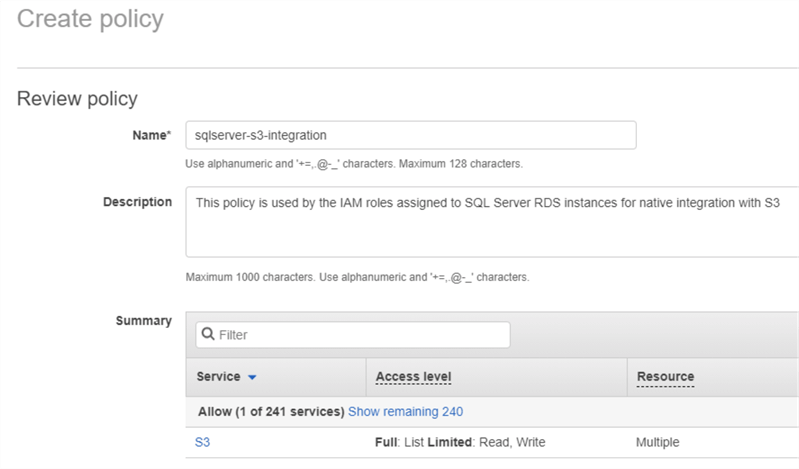
Nous appelons cette politique « sqlserver-s3-integration« .
Une fois la stratégie créée, nous devons l’affecter à un rôle IAM. Dans les images ci-dessous, nous créons un rôle IAM portant le même nom que la stratégie et lui attribuons la stratégie.
Créer le rôle :
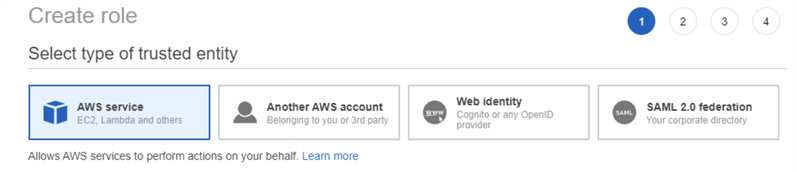
Ensuite
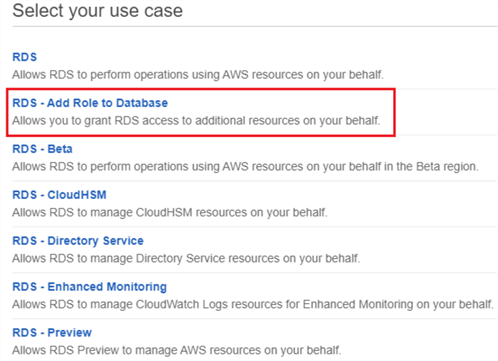
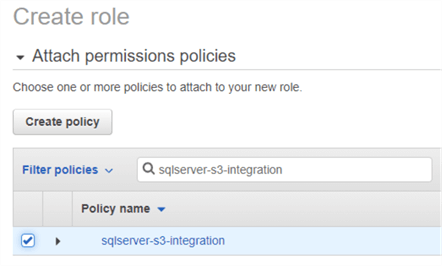
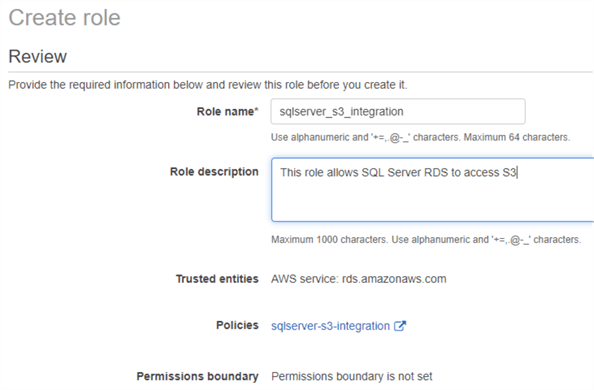
Étape 2 : Ajouter le rôle IAM à l’instance RDS SQL Server
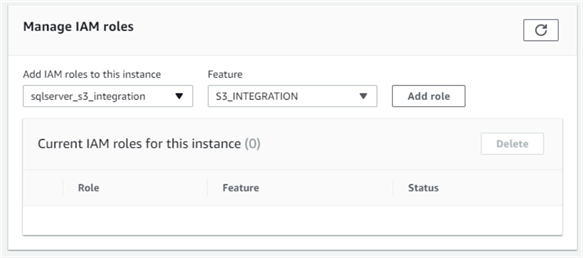
L’étape suivante consiste à attacher le rôle IAM à l’instance RDS. Cela peut se faire depuis l’onglet « Connectivité et sécurité » de la propriété de l’instance RDS. Dans la section « Gérer les rôles IAM », nous pouvons sélectionner le rôle qui vient d’être créé, puis sélectionner « S3_INTEGRATION » dans la liste déroulante « fonctionnalités » :
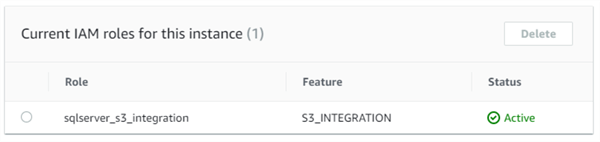
Une fois le changement effectif, le rôle a le statut « Actif » :
importer des données d’Amazon S3
L’importation des données de S3 dans une table de base de données implique deux étapes :
- Téléchargez les fichiers S3 dans un dossier local (D:\S3\) dans RDS
- Utilisez la commande BULK INSERT pour importer les fichiers de données locaux dans la table
Étape 1 : Télécharger les fichiers S3
Amazon RDS pour SQL Server est fourni avec plusieurs procédures et fonctions personnalisées. Ceux-ci sont situés dans la base de données msdb. La procédure stockée pour télécharger des fichiers depuis S3 est « rds_download_from_s3« . La syntaxe de cette procédure stockée est indiquée ici :
exec msdb.dbo.rds_download_from_s3
@s3_arn_of_file='arn:aws:s3:::/',
@rds_file_path='D:\S3\\',
@overwrite_file=1;
Le premier paramètre spécifie l’ARN d’un fichier S3.
Le deuxième paramètre définit le chemin de destination dans l’instance RDS. Le chemin racine est D:\S3\, mais nous pouvons spécifier un nom de dossier personnalisé sous celui-ci. Le dossier sera créé s’il n’existe pas déjà.
Le troisième paramètre est un indicateur. Il indique si un fichier source déjà téléchargé sera supprimé lors de la prochaine exécution de la procédure.
Nous pouvons vérifier l’état de toutes les tâches en file d’attente en exécutant la fonction « rds_fn_task_status »:
SELECT * FROM msdb.dbo.rds_fn_task_status(NULL,0);
Une fois notre fichier téléchargé sur Amazon RDS pour SQL, nous pouvons l’utiliser avec la commande bulk insert ou tout autre commande de traitement de fichier. L’essentiel est que notre fichier est maintenant disponible et visible par Amazon RDS.
Étape 2 : INSÉRER EN VRAC les données
BULK INSERT s3_integration.dbo.lapd_service_calls
FROM 'D:\S3\source_data\LAPD_Calls_for_Service_2020'
WITH (DATAFILETYPE = 'char', FIRSTROW = 2, FIELDTERMINATOR = ',', ROWTERMINATOR = '0x0a')
Quelques points à retenir
Il existe certaines limitations à l’intégration de RDS avec S3.
Tout d’abord, l’instance RDS et le compartiment S3 doivent se trouver dans la même région AWS. L’intégration interrégionale n’est pas prise en charge. De même, le propriétaire du rôle IAM et le propriétaire du compartiment S3 doivent être le même utilisateur IAM. En d’autres termes, le compartiment S3 ne peut pas se trouver dans un autre compte AWS.
Deuxièmement, seuls les fichiers sans extension ou les fichiers avec les extensions suivantes sont pris en charge :
*.bcp
*.csv
*.dat
*.fmt
*.info
*.lst
*.tbl
*.txt
*.xml
Pour intégrer un fichier dont l’extension est .bek (sauvegarde d’une base), utiliser plutôt la méthode de restauration d’une base de données
Troisièmement, le nombre maximum de fichiers autorisés pour le téléchargement local est de 100. Mais cela peut être surmonté en supprimant les fichiers une fois qu’ils sont importés dans une base de données.
Quatrièmement, la taille de fichier maximale autorisée pour le téléchargement est de 50 Go.