

Restaurer une base de données SQL Server sur une instance AWS RDS fait partie de la migration d’un système de base de données ainsi que des données vers le cloud qui est un exercice de tous les jours que l’on peut faire souvent.
Le mécanisme standard de migration de données entre deux instances de SQL Server doit utiliser le mécanisme de sauvegarde natif (sauvegarde vers un fichier .bak et restauration vers le nouveau serveur). Les instances cloud de SQL Server sont généralement des versions modifiées de SQL Server et souvent certaines fonctionnalités ne sont pas prises en charge.
AWS par exemple, fournit un moyen spécifique d’importer des sauvegardes SQL Server natives dans une instance AWS RDS de SQL Server.
Le schéma suivant montre les scénarios pris en charge par AWS :
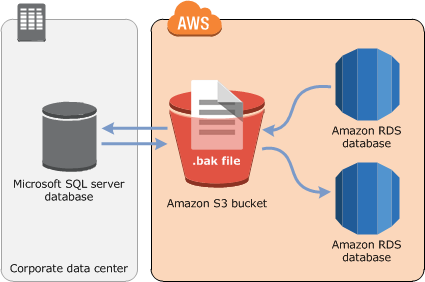
AWS RDS fournit une option dans les groupes d’options que nous pouvons utiliser pour importer une sauvegarde SQL Server dans une instance AWS RDS de SQL Server.
un compte S3 (Simple Storage Service) qui est un équivalent d’Azure Blog Storage est nécessaire pour sauvegarder le .bak de la base de données.
Étapes pour restaurer une base de données SQL Server sur une instance AWS RDS
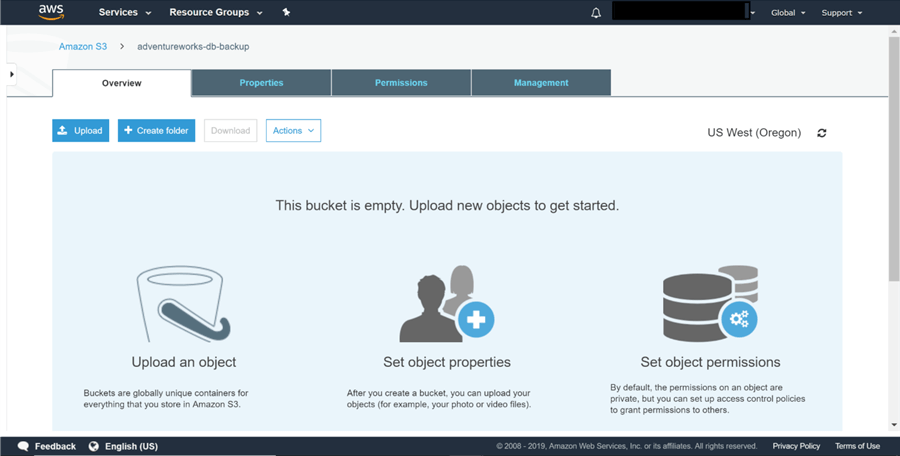
1) Connectez-vous à votre compte AWS et créez un compartiment (qui ressemble à un dossier) sur le tableau de bord S3, comme indiqué ci-dessous. Nous allons stocker l’exemple de sauvegarde SQL Server dans ce compartiment. Ici, j’ai nommé le bucket adventureworks-db-backup.
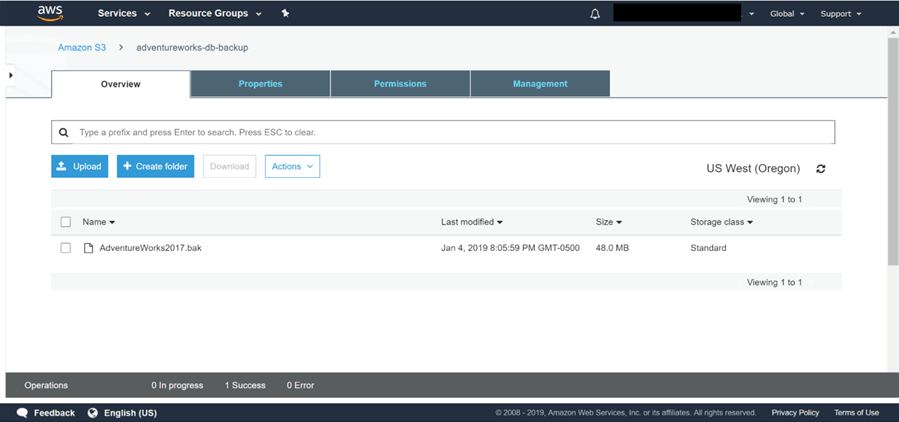
2) Téléchargez le fichier de sauvegarde dans ce compartiment à l’aide du bouton de téléchargement. J’ai téléchargé le fichier de sauvegarde de la base de données AdventureWorks comme indiqué ci-dessous.
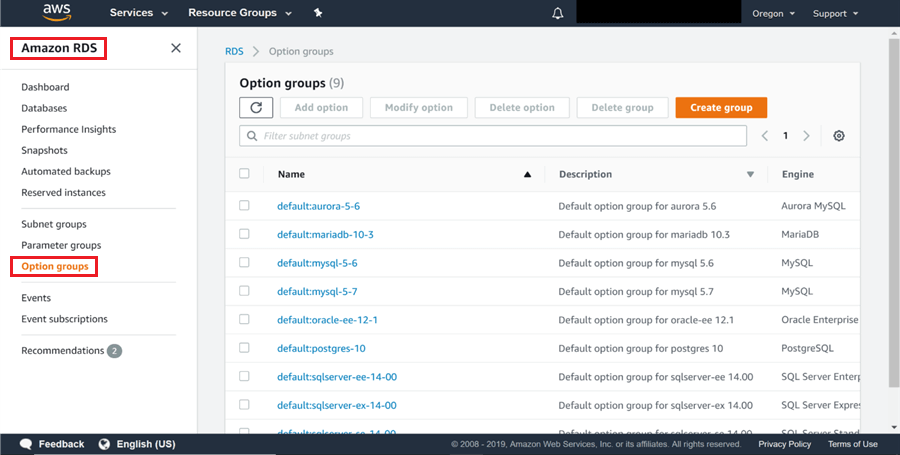
3) Une fois la sauvegarde téléchargée, vous pouvez accéder au tableau de bord RDS en cliquant sur l’option Service de base de données relationnelle dans la catégorie Base de données sur la page d’accueil de la console Amazon. En supposant que vous ayez créé une instance RDS SQL Server à l’aide des options par défaut, vous auriez un groupe d’options par défaut associé à cette instance. La même chose peut être trouvée dans l’onglet Groupes d’options comme indiqué ci-dessous.
4) Nous devons d’abord créer un groupe d’options personnalisé, puis ajouter l’option de sauvegarde et de restauration. Une fois cela fait, nous associerons ensuite ce nouveau groupe d’options à l’instance AWS RDS de SQL Server. Pour créer ce nouveau groupe d’options, cliquez sur le bouton Créer un groupe comme indiqué ci-dessus, et vous serez invité à remplir les détails de ce nouveau groupe d’options comme indiqué ci-dessous. Fournissez un nom et une description pertinents, sélectionnez SQL Server comme moteur et sélectionnez la dernière version majeure du moteur dans la liste. Après avoir rempli ces détails, cliquez sur le bouton Créer pour créer le groupe d’options.
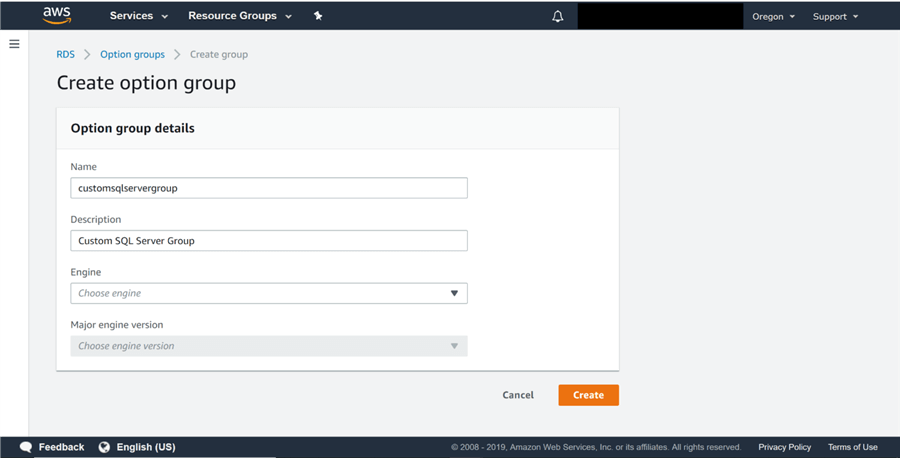
5) Une fois le groupe d’options créé, vous le trouverez répertorié sous l’onglet Groupes d’options, comme indiqué ci-dessous. Sélectionnez ce groupe d’options et vous constaterez que le bouton d’option Ajouter est activé. Cliquez sur ce bouton pour ajouter l’option de sauvegarde et de restauration au groupe d’options nouvellement créé.
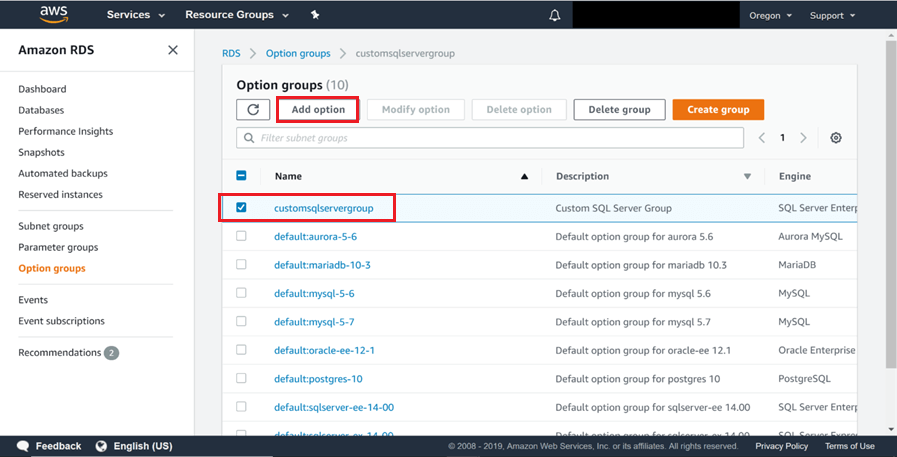
6) Sélectionnez l’option SQLSERVER_BACKUP_RESTORE dans la liste des options. Cet ajout nécessite un rôle de gestion des identités et des accès pour cette option. L’option par défaut consiste à créer un nouveau rôle. Laissez cette option par défaut et faites défiler vers le bas.
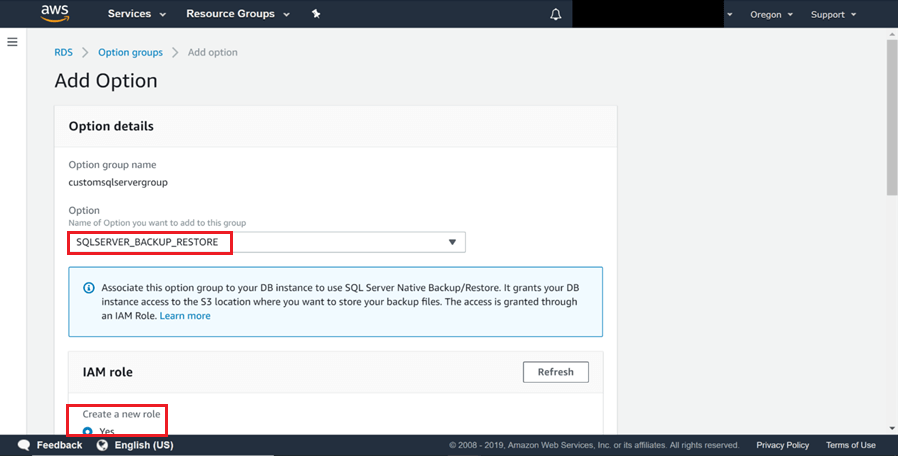
7) Sélectionner le compartiment S3 contenant les fichiers de sauvegarde. Sélectionnez le compartiment dans lequel nous avions placé le fichier de sauvegarde comme indiqué ci-dessous. Laissez l’option de cryptage par défaut pour l’instant, sélectionnez l’option Appliquer immédiatement et cliquez sur le bouton Ajouter une option.

8) Maintenant que nous avons créé un groupe d’options et modifié l’option également, il est temps de l’associer à l’instance SQL Server en modifiant l’instance. Pour ce faire, cliquez sur l’option bases de données, puis cliquez sur le bouton Modifier comme indiqué ci-dessous.
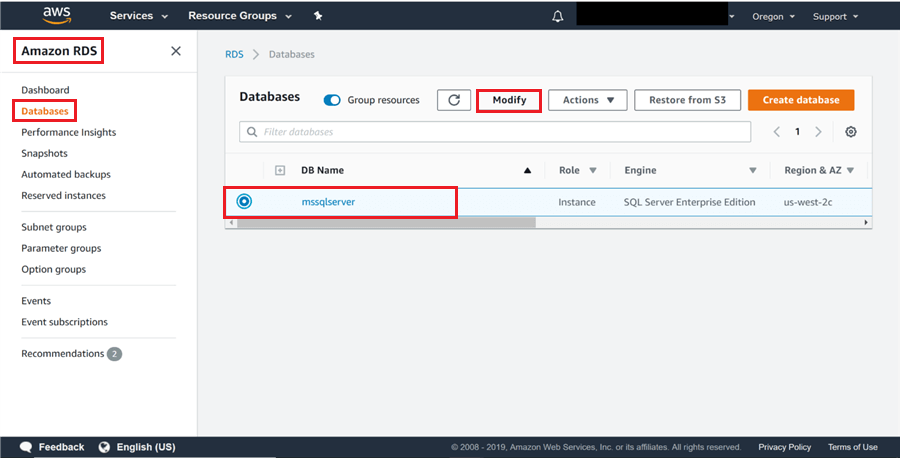
9) Après avoir cliqué sur le bouton Modifier, une longue liste de détails s’ouvrira pour modification. Faites défiler jusqu’aux options de la base de données et remplacez le groupe d’options nouvellement créé par celui que nous avons créé aux étapes précédentes. Une fois terminé, cliquez sur le bouton Suivant.

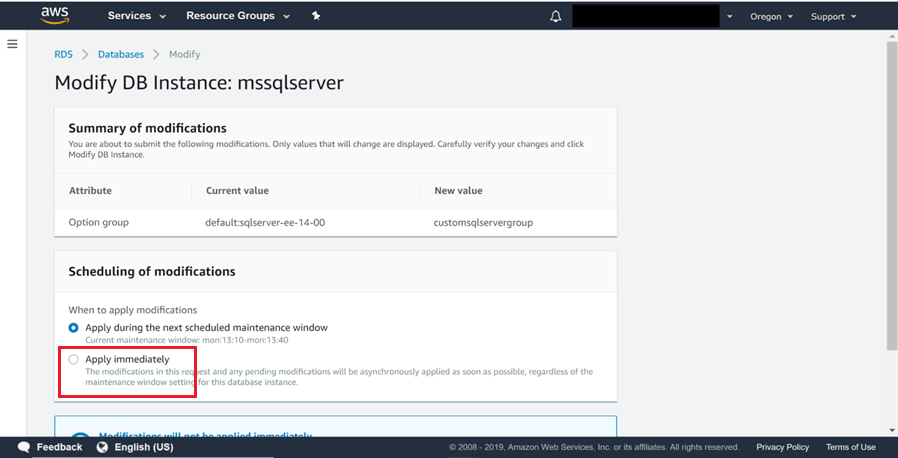
10) Vous verrez alors un résumé des modifications comme indiqué ci-dessous. Sélectionnez Appliquer immédiatement et cliquez sur le bouton Appliquer. Cela appliquera immédiatement les modifications à l’instance SQL Server.
11) Il est maintenant temps d’importer la sauvegarde dans SQL Server. Ouvrez SQL Server Management Studio (SSMS) et connectez-vous à l’instance SQL Server sur AWS, en utilisant le point de terminaison du serveur comme nom de serveur, le mode d’authentification comme SQL Server et en utilisant les informations d’identification de connexion au serveur.
Après avoir réussi à vous connecter au serveur, exécutez le code ci-dessous. Nous exécutons la procédure stockée rds_restore_database qui est une procédure stockée spécifique à AWS.
Il a besoin de deux paramètres, @restore_db_name (c’est-à-dire le nom de la base de données qui sera utilisée une fois la base de données restaurée sur l’instance SQL Server), et le deuxième paramètre est @s3_arn_to_restore_from (c’est-à-dire Amazon Resource Name (ARN) du fichier que nous essayez de restaurer).
La commande exacte :
exec msdb.dbo.rds_backup_database
@source_db_name='database_name',
@s3_arn_to_backup_to='arn:aws:s3:::bucket_name/file_name.extension'
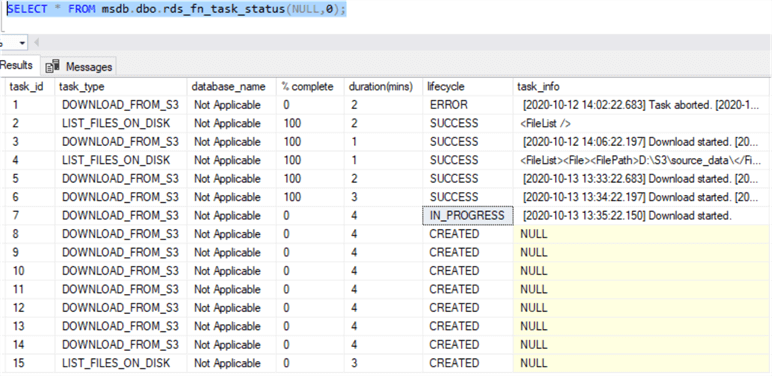
Connaître l’avancement de la restauration
Une fois on exécute la commande rds_backup_database, on pourra suivre le statut de la restauration avec cette commande
SELECT * FROM msdb.dbo.rds_fn_task_status(NULL,id);
SQL Server fournit l’id à mettre dans la requête une fois on exécute la commande restaure.
On peut avoir 4 types de statut :
- CREATED : création du job de la restauration
- IN_PROGRESS : avancement de la restauration
- SUCCESS : succès de la restauration
- ERROR : erreur lors de la restauration, et on peut voir le détail de l’erreur pour la corriger
Conclusion
Une fois ces paramètres fournis et le code exécuté, la base de données doit être restaurée.
Après une restauration réussie, nous pouvons commencer à interroger la base de données. On l’interroge comme n’importe quelle autre base de données locale, comme indiqué ci-dessous.

Références
Importing and exporting SQL Server databases using native backup and restore
Restore SQL Server database backup to an AWS RDS Instance of SQL Server
1 commentaire